
构建智能外部信息召回神器大模型的力量与应用 引言 在信息爆炸的时代,企业和研究机构面临着海量的外部信息,如何高效、准确地召回相关信息成为了一项挑战。大模型,尤其是基于深度学习的自然语言处理模型,因其强大的数据处理和理解能力,成为了打造外部信息召回神器的核心技术。本文将探讨如何利用大模型构建一个高效的外部信息召回系统。 1.大模型的基本原理与优势 大模型通常指的是参数数量巨大的深度学习模型,如GPT-3、BERT等。这些模型通过在大规模数据集上进行预训练,能够捕捉到丰富的语言规律和知识。在信息
构建智能外部信息召回神器:大模型的力量与应用
引言
在信息爆炸的时代,企业和研究机构面临着海量的外部信息,如何高效、准确地召回相关信息成为了一项挑战。大模型,尤其是基于深度学习的自然语言处理模型,因其强大的数据处理和理解能力,成为了打造外部信息召回神器的核心技术。本文将探讨如何利用大模型构建一个高效的外部信息召回系统。
1. 大模型的基本原理与优势
大模型通常指的是参数数量巨大的深度学习模型,如GPT3、BERT等。这些模型通过在大规模数据集上进行预训练,能够捕捉到丰富的语言规律和知识。在信息召回领域,大模型的优势主要体现在以下几个方面:
理解能力
:大模型能够理解复杂的语言结构和语义,从而更准确地匹配用户查询与信息库中的内容。
泛化能力
:预训练的大模型具有良好的泛化能力,能够处理未见过的数据,适应多变的查询需求。
学习能力
:通过微调,大模型可以快速适应特定领域的信息召回任务,提高召回的准确性和相关性。2. 构建外部信息召回系统的关键步骤
2.1 数据收集与预处理
构建外部信息召回系统的第一步是收集和预处理数据。这包括从互联网、数据库、文献库等渠道收集相关信息,并进行清洗、格式化等预处理工作,以确保数据的质量和可用性。
2.2 模型选择与预训练
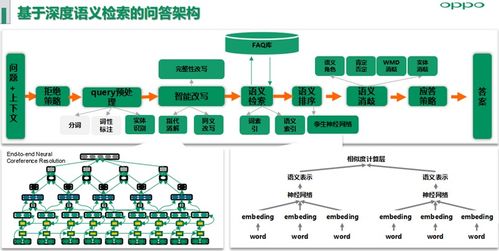
选择合适的大模型是关键。根据召回任务的特点,可以选择如BERT、RoBERTa等模型进行预训练。预训练通常在大型通用语料库上进行,以使模型掌握基本的语言理解能力。
2.3 领域微调
为了提高召回的准确性,需要对模型进行领域特定的微调。这通常涉及在特定领域的数据集上进行额外的训练,使模型能够更好地理解和召回该领域的信息。
2.4 召回策略与优化
召回策略包括如何根据用户查询生成召回候选集,以及如何对候选集进行排序。大模型可以用来理解查询意图,生成相关的关键词或短语,进而从信息库中召回相关内容。通过不断优化召回算法和模型参数,可以提高召回的效率和准确性。
3. 实际应用案例分析
以医疗领域为例,介绍如何利用大模型构建外部信息召回系统。收集医疗文献、病例报告等数据,并进行预处理。使用预训练的BERT模型进行微调,使其能够理解和召回医疗领域的专业信息。通过优化召回策略,如结合医疗知识图谱,提高召回的相关性和准确性。
4. 面临的挑战与未来展望
尽管大模型在信息召回方面展现出巨大潜力,但仍面临一些挑战,如数据隐私保护、模型解释性、计算资源需求等。未来,随着技术的进步,我们可以期待更加高效、智能的信息召回系统,它们将更好地服务于科研、商业分析等领域。
结语
大模型作为构建外部信息召回神器的核心技术,其强大的理解能力和泛化能力为信息召回提供了新的解决方案。通过精心设计的数据处理流程和模型优化策略,可以构建出高效、准确的信息召回系统,帮助企业和研究机构在海量信息中快速找到所需内容。随着技术的不断发展,大模型在信息召回领域的应用将更加广泛和深入。








韵璟
这家伙太懒。。。
- 暂无未发布任何投稿。


