
如何用大模型打造外部信息召回神器系统
构建外部信息召回神器:使用大模型的方法与指导
在信息检索领域,构建一个高效的外部信息召回(External Information Retrieval)系统对于许多应用至关重要,尤其是在搜索引擎、推荐系统和自然语言处理任务中。使用大模型来打造外部信息召回神器可以显著提高检索质量和效率。本文将探讨如何利用大模型实现这一目标,并提供实施的指导建议。
理解外部信息召回
外部信息召回是指在处理特定任务(如查询处理或推荐系统)时,通过访问外部数据源(如互联网或专业数据库),以提升信息检索或推荐的准确性、全面性和实时性。这种方法可以弥补内部数据或模型的局限性,使系统更加智能和全面。
利用大模型的优势
大模型(如GPT系列、BERT等)因其在语言理解和文本处理任务中的卓越表现而受到青睐。将大模型应用于外部信息召回有以下几个优势:
1.
语义理解能力强
:大模型能够更好地理解自然语言文本的语义和上下文,从而更准确地匹配查询和外部信息源。2.
多语言支持
:大多数大模型都经过了多语言训练,能够处理不同语言的查询和文本,提升了系统的国际化能力。3.
端到端训练
:大模型通常能够通过端到端的训练方式优化整个信息检索流程,从查询到信息检索结果的输出,提升系统的整体性能。4.
泛化能力强
:大模型通过大规模数据的训练,学习到了丰富的语言模式和知识表示,能够更好地泛化到未见过的数据和查询。 步骤和实施指南
1. 数据收集与预处理
选择外部信息源
:根据应用场景选择合适的外部数据源,例如专业领域的文档、新闻网站、社交媒体或在线数据库。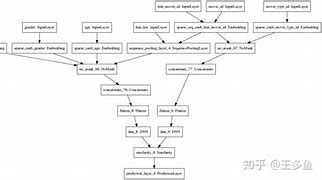
数据抽取与清洗
:从选定的外部数据源中抽取数据,并进行清洗和预处理以适应后续模型的输入格式和要求。这包括文本的分词、去除停用词、实体识别等。 2. 模型选择与调优
选择合适的大模型
:根据任务需求选择适合的大模型,如GPT系列用于生成型任务、BERT用于理解型任务等。也可以考虑使用预训练模型的微调或迁移学习技术。
模型集成
:考虑将多个模型进行集成,以提升检索的多样性和覆盖率。可以通过投票、融合或级联等技术实现集成。
模型调优
:针对特定任务进行模型的调优和优化,包括超参数调整、输入数据的增强、模型蒸馏(distillation)等。 3. 查询处理与匹配
查询解析
:设计并实现查询解析系统,将用户的查询转换为模型可处理的格式,例如向量表示、语义标记或注意力机制输入。
信息匹配
:利用大模型进行信息匹配,可以采用检索式或生成式的方法,通过语义匹配来获取外部信息源中与查询相关的内容。 4. 结果集成与反馈
结果过滤与排序
:对从外部信息源中检索到的结果进行过滤和排序,确保输出的信息质量和相关性。
反馈机制
:引入用户反馈机制,监控用户对检索结果的满意度,并根据反馈调整模型或重新训练,持续优化外部信息召回的效果。 5. 系统部署与监控
部署架构设计
:设计高效的系统架构,考虑模型的实时性需求和扩展性。
性能监控与调优
:建立监控系统,实时跟踪外部信息召回系统的性能指标(如响应时间、准确率、召回率等),并进行持续的性能调优。 案例与实际应用
搜索引擎优化
:利用大模型提升搜索引擎的检索效果,特别是在处理长尾查询和复杂语境时的效果显著。
推荐系统增强
:将大模型应用于推荐系统的外部内容扩展,提升个性化推荐的深度和广度。
信息检索应用
:在企业内部或特定领域的信息检索系统中,通过大模型实现更智能的信息过滤和检索。 总结
利用大模型打造外部信息召回神器可以显著提升系统的智能化和用户体验。关键在于选择合适的模型、优化数据流程、设计有效的查询处理与匹配算法,并通过系统化的部署与监控持续优化系统性能。随着大模型技术的发展和应用场景的丰富,外部信息召回的实现将越来越高效和精确。








婉聆
这家伙太懒。。。
- 暂无未发布任何投稿。


